 Korta byte: Webcrawler är ett program som surfar på Internet (World Wide Web) på ett förutbestämt, konfigurerbart och automatiserat sätt och utför en given åtgärd på genomsökt innehåll. Sökmotorer som Google och Yahoo använder spidering som ett sätt att tillhandahålla uppdaterad information.
Korta byte: Webcrawler är ett program som surfar på Internet (World Wide Web) på ett förutbestämt, konfigurerbart och automatiserat sätt och utför en given åtgärd på genomsökt innehåll. Sökmotorer som Google och Yahoo använder spidering som ett sätt att tillhandahålla uppdaterad information.
Webhose.io, ett företag som ger direkt tillgång till levande data från hundratusentals forum, nyheter och bloggar, publicerade den 12 augusti 2015 artiklarna som beskriver en liten, flera trådad webbsökare skriven i python. Denna python-webbsökare kan genomsöka hela webben åt dig. Ran Geva, författaren till denna lilla python-webcrawler säger att:
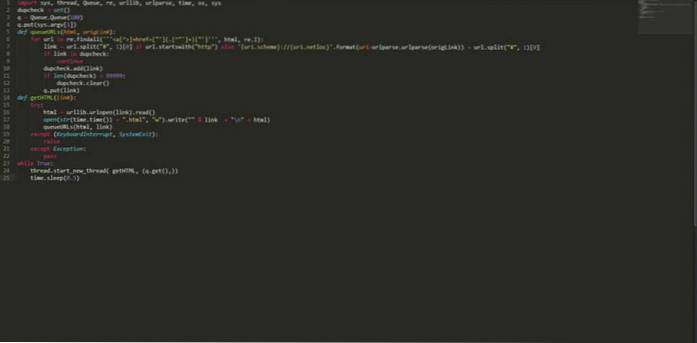
Jag skrev som "Dirty", "Iffy", "Bad", "Inte särskilt bra". Jag säger, det gör jobbet och laddar ner tusentals sidor från flera sidor på några timmar. Ingen installation krävs, ingen extern import, kör bara följande pythonkod med en utsäde och luta dig tillbaka (eller gör något annat eftersom det kan ta några timmar eller dagar beroende på hur mycket data du behöver).Den pythonbaserade flertrådade sökroboten är ganska enkel och mycket snabb. Den kan upptäcka och eliminera dubbla länkar och spara både källa och länk som senare kan användas för att hitta inkommande och utgående länkar för att beräkna sidrankning. Det är helt gratis och koden listas nedan:
importera sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): för webbadress i re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): länk = url.split ("#", 1) [0] om url.startar med ( "http") annat 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] om länk i dubbelkontroll : fortsätt dupcheck.add (länk) om len (dupcheck)> 99999: dupcheck.clear () q.put (länk) def getHTML (länk): försök: html = urllib.urlopen (länk) .läs () öppna (str (time.time ()) + ".html", "w"). skriv (""% link + "\ n" + html) queURLs (html, länk) förutom (KeyboardInterrupt, SystemExit): höj utom Exception: pass medan True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Spara ovanstående kod med något namn kan säga “myPythonCrawler.py”. För att börja genomsöka vilken webbplats som helst, skriv bara:
$ python myPythonCrawler.py https://fossbytes.com
Luta dig tillbaka och njut av den här webbsökaren i python. Den laddar ner hela webbplatsen åt dig.
Bli ett proffs i Python med dessa kurser
Gillar du den här döda enkla pythonbaserade flertrådade webbsökaren? Låt oss veta i kommentarer.
Läs också: Så här skapar du startbar USB utan någon programvara i Windows 10